К нам обратился клиент с задачей автоматизировать сопоставление двух справочников: внутреннего справочника товаров и справочника, который формируют поставщики. Цель — предложить каждому менеджеру по закупкам наиболее подходящую номенклатуру из справочника поставщика на основе уже существующих у него товаров.
На первый взгляд задача казалась простой. Например, менеджер Иванов отвечает за закупки товаров по бренду Apple, значит, ему нужно автоматически предложить те позиции из справочника поставщика, которые максимально близки к его текущему ассортименту. Однако при ручном подборе оказалось, что это крайне трудоемкий процесс:
- наименования часто отличаются даже в рамках одного производителя,
- группы и подгруппы могут называться по-разному,
- есть множество нюансов, которые сложно учесть без автоматизации.
Это было лишь началом. В первой версии приложения вся логика сопоставления выполнялась на стороне Qlik, однако платформа оказалась малопригодной для таких задач: Qlik не справляется с тяжелыми циклическими вычислениями и посимвольным сравнением строк. В результате загрузка приложения занимала до 10 часов.
Кроме того, на практике вскрылись дополнительные нюансы, неучтенные изначально:
- сравнение производителей должно быть строгое (без частичных совпадений);
- одна и та же позиция из справочника поставщика не должна предлагаться разным менеджерам;
- если товар уже присутствует во внутреннем справочнике, его не нужно сопоставлять повторно.
Все эти детали потребовали переноса логики из Qlik в более гибкую и производительную среду. Поэтому решили перенести алгоритм сравнения на Python, а Qlik Sense использовать только для формирования входных данных и последующего анализа.
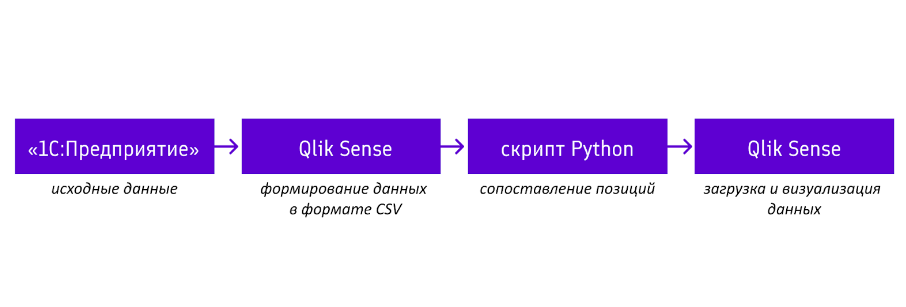
Для автоматизации процесса сравнения с помощью Python использовали библиотеки pandas, rapidfuzz, multiprocessing. Итоговая концепция получилась следующая.
Структура входных данных
В качестве формата обмена данными между системами был выбран CSV, поскольку он поддерживается как в Qlik Sense, так и в Python, а также обеспечивает простоту интеграции и удобство предварительной обработки.
Товары.csv – внутренний справочник с колонками:
Производитель, Группа, Подгруппа, Товар, Менеджер, Артикул
СправочникПоставщика.csv – справочник поставщика:
Производитель, Группа, Подгруппа, Номенклатура, Артикул, Поставщик
Проценты.csv – настройки порогов сравнения в формате (необходимо, чтобы уменьшить декартово произведение):
Наименование; Проценты
степень_производителей;100
степень_групп;40
степень_подгрупп;40
степень_товары;40
Низкие пороги для групп и подгрупп позволяют компенсировать разнобой в описаниях, т. к. поставщики часто называют категории по-разному.
Схема логики функций
- Главная функция, которая запускает весь процесс:
- загружает CSV-файлы: Товары.csv, СправочникПоставщика.csv, Проценты.csv;
- преобразует процентные пороги в словарь;
- делит справочник товары на части по количеству доступных процессов;
- запускает многопроцессную обработку каждой части;
- собирает все результаты в один список;
- фильтрует результат;
- сохраняет финальный DataFrame в CSV для анализа в Qlik Sense.
- Обработка частей товаров. Обрабатывает одну часть справочника товаров в сравнении с полным справочником соответствий. Логика сравнения каскадная:
- Сравнение производителей.
- Если значение больше порога по производителям, идем дальше.
- Сравнение групп.
- Сравниваются группы товаров и соответствий.
- При достижении порога по группам → следующий шаг.
- Сравнение названий товаров.
- Товар (из справочника товаров) сравнивается с Номенклатурой (из справочника поставщика).
- Считается:
- % совпадения (с помощью fuzz.ratio. Это число совпавших символов / максимальное число символов из двух товаров) - Если % больше порога по товарам, запись сохраняется.
- Если товар еще не сопоставлен идет сравнение по подгруппам.
- Аналогичная логика, но на уровне подгрупп.
- Применяется, если сравнение по группе не дало результата.
- Результат.
- Возвращает список словарей с совпадениями:
- Менеджер, поставщик, артикул, производитель, группы, подгруппы, названия, проценты и длины совпадений
- Возвращает список словарей с совпадениями:
- Сравнение производителей.
- Фильтр по менеджерам. Цель — оставить только те строки, где указан «главный» менеджер по закупкам для каждого производителя:
- проходит по каждому уникальному производителю из результатов;
- происходит определение менеджера по производителю:
- считает количество уникальных товаров по каждому менеджеру;
- выбирает того, у кого их больше всего;
- отфильтровывает строки, в которых менеджер ≠ выбранному.
- Определение менеджера по производителю.
- Фильтрует DataFrame товары по конкретному производителю.
- Группирует по Менеджеру, считает уникальные Товар.
- Возвращает менеджера с максимумом товаров.
- Длина совпавших символов.
- Используется библиотека SequenceMatcher для оценки общего числа совпавших символов.
- Помогает дополнительно понять качество сопоставления, особенно при одинаковом % совпадения.
Итог
Финальный результат сохраняется в Сопоставления.csv и содержит только те совпадения, которые прошли фильтрацию по всем уровням и назначены «главному» менеджеру для дальнейшей загрузки, анализа и визуализации в Qlik Sense.
Приложение в Qlik Sense
С помощью Qlik Sense происходит подготовка данных для Python и их непосредственный анализ в приложении.
Дашборд «Сравнение»
Эта витрина разделена на 3 части.
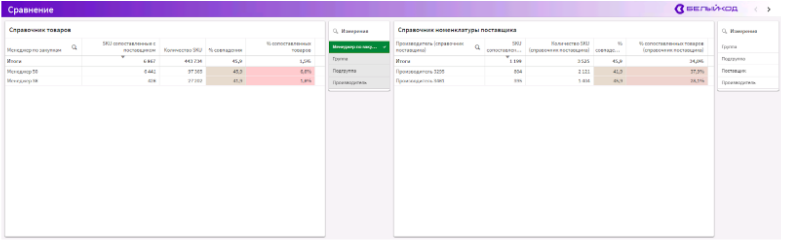
Первая часть сводная информация. Видно сколько товаров сопоставлено в разных разрезах и какой средний % совпадения.
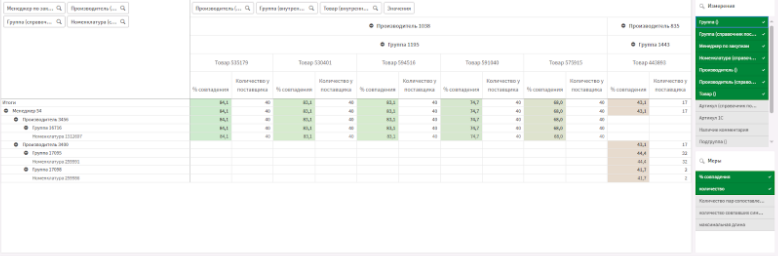
Во второй части представлена сводная таблица, где можно подробно рассмотреть, что с чем сопоставилось и сколько товаров присутствует у поставщика. Также есть плоская таблица для удобной выгрузки в Excel.
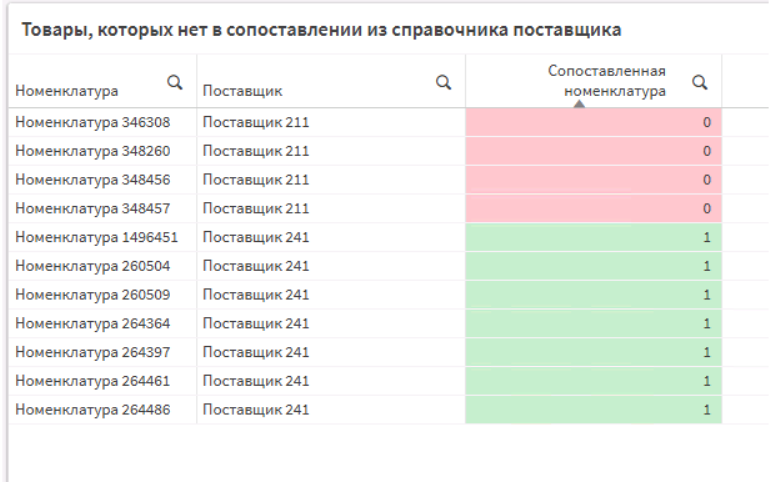
В нижней части дашборда клиент попросил добавить таблицу, где будет видно, какие товары сопоставились, а какие нет, для быстрого поиска и возможности последующего анализа для доработки алгоритма.
Дашборд «Справочник поставщика»
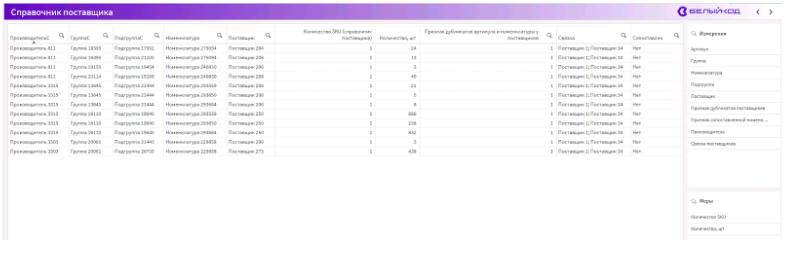
Выведены все разрезы из справочника поставщика с добавлением полей по заказу клиента – «Признак дубликатов» и «Связка». При помощи признака дубликатов можно быстро отфильтровать позиции, которые повторяются в справочнике, но находятся у разных поставщиков. Поле «Связка» показывает у каких поставщиков найдены дубликаты товаров. Бывает такое, что у четырех поставщиков есть один и тот же товар, но у кого-то его больше.
Дашборд «Комментарии из Google-таблицы»
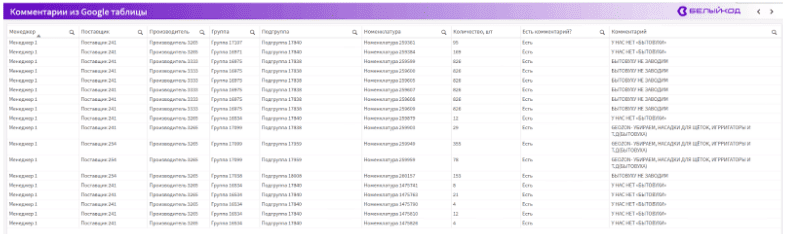
Следующий дашборд служит дополнительной фильтрацией для сравнения справочников, бывает такое, что товар сопоставили, но по какой-то причине не должен быть заведен. Клиент вносит в Google-таблицу комментарии и по какому признаку этот комментарий привязать, и алгоритм Python сам понимает, к чему состыковать комментарий, по производителю, группе, подгруппе и т. д.
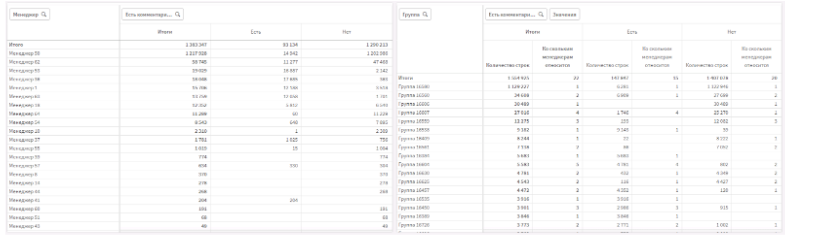
Представлены сводные таблицы для фильтрации по признаку заполнен ли комментарий, товары, где комментария нет, отправляют менеджерам на рассмотрение в закупку.
Итог
Реализация сопоставления справочников с использованием Python и последующего анализа в Qlik Sense стала эффективным решением для автоматизации трудоемкой и повторяющейся задачи, которую ранее выполняли вручную или средствами 1С.
Что дала связка Python + Qlik Sense

Результат
Прежде всего, ощутимо изменилось время обработки. Если через Qlik Sense на это требовалось около 10 часов, то при использовании Python время сократилось до 30-40 минут, то есть более чем в 10 раз. Также снизилось количество ошибок сопоставления, благодаря настройкам параметров. На всех уровнях теперь единая логика сопоставления: производитель → группа → подгруппа → товар. Все работает по расписанию, при этом независимо друг от друга.
В целом, благодаря такой архитектуре удалось найти баланс между вычислительной мощностью (Python) и гибкостью визуального анализа (Qlik Sense). Теперь с помощью легко читаемых дашбордов можно полностью контролировать процесс.
Решение универсальное и масштабируемое. Алгоритм работает в многопоточном режиме и логика при любых объемах данных останется неизменной, а если количество данных значительно вырастет, необходимо будет лишь добавить мощностей процессора. Универсальность обеспечивается гибкой настройкой параметров сопоставления, а также кроссплатформенностью Python для любых систем.